 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKeyword Spotting
Keyword spotting (KWS) is an important technique for speech applications, which enables users to activate devices by speaking a keyword phrase.
Papers and Code
EdgeSpot: Efficient and High-Performance Few-Shot Model for Keyword Spotting
Jan 22, 2026We introduce an efficient few-shot keyword spotting model for edge devices, EdgeSpot, that pairs an optimized version of a BC-ResNet-based acoustic backbone with a trainable Per-Channel Energy Normalization frontend and lightweight temporal self-attention. Knowledge distillation is utilized during training by employing a self-supervised teacher model, optimized with Sub-center ArcFace loss. This study demonstrates that the EdgeSpot model consistently provides better accuracy at a fixed false-alarm rate (FAR) than strong BC-ResNet baselines. The largest variant, EdgeSpot-4, improves the 10-shot accuracy at 1% FAR from 73.7% to 82.0%, which requires only 29.4M MACs with 128k parameters.
MATE: Matryoshka Audio-Text Embeddings for Open-Vocabulary Keyword Spotting
Jan 20, 2026Open-vocabulary keyword spotting (KWS) with text-based enrollment has emerged as a flexible alternative to fixed-phrase triggers. Prior utterance-level matching methods, from an embedding-learning standpoint, learn embeddings at a single fixed dimensionality. We depart from this design and propose Matryoshka Audio-Text Embeddings (MATE), a dual-encoder framework that encodes multiple embedding granularities within a single vector via nested sub-embeddings ("prefixes"). Specifically, we introduce a PCA-guided prefix alignment: PCA-compressed versions of the full text embedding for each prefix size serve as teacher targets to align both audio and text prefixes. This alignment concentrates salient keyword cues in lower-dimensional prefixes, while higher dimensions add detail. MATE is trained with standard deep metric learning objectives for audio-text KWS, and is loss-agnostic. To our knowledge, this is the first application of matryoshka-style embeddings to KWS, achieving state-of-the-art results on WSJ and LibriPhrase without any inference overhead.
ReCCur: A Recursive Corner-Case Curation Framework for Robust Vision-Language Understanding in Open and Edge Scenarios
Jan 06, 2026Corner cases are rare or extreme scenarios that drive real-world failures, but they are difficult to curate at scale: web data are noisy, labels are brittle, and edge deployments preclude large retraining. We present ReCCur (Recursive Corner-Case Curation), a low-compute framework that converts noisy web imagery into auditable fine-grained labels via a multi-agent recursive pipeline. First, large-scale data acquisition and filtering expands a domain vocabulary with a vision-language model (VLM), crawls the web, and enforces tri-modal (image, description, keyword) consistency with light human spot checks to yield refined candidates. Next, mixture-of-experts knowledge distillation uses complementary encoders (e.g., CLIP, DINOv2, BEiT) for kNN voting with dual-confidence activation and uncertainty sampling, converging to a high-precision set. Finally, region-evidence VLM adversarial labeling pairs a proposer (multi-granularity regions and semantic cues) with a validator (global and local chained consistency) to produce explainable labels and close the loop. On realistic corner-case scenarios (e.g., flooded-car inspection), ReCCur runs on consumer-grade GPUs, steadily improves purity and separability, and requires minimal human supervision, providing a practical substrate for downstream training and evaluation under resource constraints. Code and dataset will be released.
Joint Multimodal Contrastive Learning for Robust Spoken Term Detection and Keyword Spotting
Dec 16, 2025



Acoustic Word Embeddings (AWEs) improve the efficiency of speech retrieval tasks such as Spoken Term Detection (STD) and Keyword Spotting (KWS). However, existing approaches suffer from limitations, including unimodal supervision, disjoint optimization of audio-audio and audio-text alignment, and the need for task-specific models. To address these shortcomings, we propose a joint multimodal contrastive learning framework that unifies both acoustic and cross-modal supervision in a shared embedding space. Our approach simultaneously optimizes: (i) audio-text contrastive learning, inspired by the CLAP loss, to align audio and text representations and (ii) audio-audio contrastive learning, via Deep Word Discrimination (DWD) loss, to enhance intra-class compactness and inter-class separation. The proposed method outperforms existing AWE baselines on word discrimination task while flexibly supporting both STD and KWS. To our knowledge, this is the first comprehensive approach of its kind.
OASI: Objective-Aware Surrogate Initialization for Multi-Objective Bayesian Optimization in TinyML Keyword Spotting
Dec 17, 2025



Voice assistants utilize Keyword Spotting (KWS) to enable efficient, privacy-friendly activation. However, realizing accurate KWS models on ultra-low-power TinyML devices (often with less than $<2$ MB of flash memory) necessitates a delicate balance between accuracy with strict resource constraints. Multi-objective Bayesian Optimization (MOBO) is an ideal candidate for managing such a trade-off but is highly initialization-dependent, especially under the budgeted black-box setting. Existing methods typically fall back to naive, ad-hoc sampling routines (e.g., Latin Hypercube Sampling (LHS), Sobol sequences, or Random search) that are adapted to neither the Pareto front nor undergo rigorous statistical comparison. To address this, we propose Objective-Aware Surrogate Initialization (OASI), a novel initialization strategy that leverages Multi-Objective Simulated Annealing (MOSA) to generate a seed Pareto set of high-performing and diverse configurations that explicitly balance accuracy and model size. Evaluated in a TinyML KWS setting, OASI outperforms LHS, Sobol, and Random initialization, achieving the highest hypervolume (0.0627) and the lowest generational distance (0.0) across multiple runs, with only a modest increase in computation time (1934 s vs. $\sim$1500 s). A non-parametric statistical analysis using the Kruskal-Wallis test ($H = 5.40$, $p = 0.144$, $η^2 = 0.0007$) and Dunn's post-hoc test confirms OASI's superior consistency despite the non-significant overall difference with respect to the $α=0.05$ threshold.
Continual Learning for Acoustic Event Classification
Dec 10, 2025


Continuously learning new classes without catastrophic forgetting is a challenging problem for on-device acoustic event classification given the restrictions on computation resources (e.g., model size, running memory). To alleviate such an issue, we propose two novel diversity-aware incremental learning method for Spoken Keyword Spotting and Environmental Sound Classification. Our method selects the historical data for the training by measuring the per-sample classification uncertainty. For the Spoken Keyword Spotting application, the proposed RK approach introduces a diversity-aware sampler to select a diverse set from historical and incoming keywords by calculating classification uncertainty. As a result, the RK approach can incrementally learn new tasks without forgetting prior knowledge. Besides, the RK approach also proposes data augmentation and knowledge distillation loss function for efficient memory management on the edge device. For the Environmental Sound Classification application, we measure the uncertainty by observing how the classification probability of data fluctuates against the parallel perturbations added to the classifier embedding. In this way, the computation cost can be significantly reduced compared with adding perturbation to the raw data. Experimental results show that the proposed RK approach achieves 4.2% absolute improvement in terms of average accuracy over the best baseline on Google Speech Command dataset with less required memory. Experimental results on the DCASE 2019 Task 1 and ESC-50 dataset show that our proposed method outperforms baseline continual learning methods on classification accuracy and computational efficiency, indicating our method can efficiently and incrementally learn new classes without the catastrophic forgetting problem for on-device environmental sound classification
LOKI: a 0.266 pJ/SOP Digital SNN Accelerator with Multi-Cycle Clock-Gated SRAM in 22nm
Nov 14, 2025
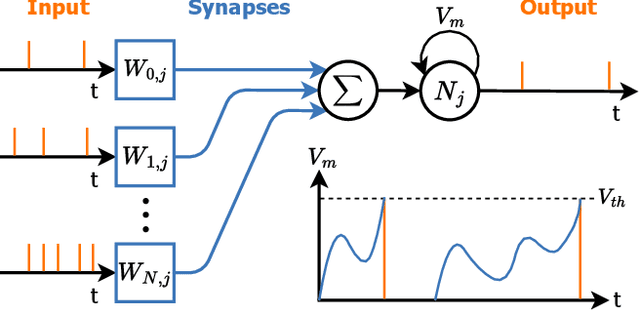


Bio-inspired sensors like Dynamic Vision Sensors (DVS) and silicon cochleas are often combined with Spiking Neural Networks (SNNs), enabling efficient, event-driven processing similar to biological sensory systems. To realize the low-power constraints of the edge, the SNN should run on a hardware architecture that can exploit the sparse nature of the spikes. In this paper, we introduce LOKI, a digital architecture for Fully-Connected (FC) SNNs. By using Multi-Cycle Clock-Gated (MCCG) SRAMs, LOKI can operate at 0.59 V, while running at a clock frequency of 667 MHz. At full throughput, LOKI only consumes 0.266 pJ/SOP. We evaluate LOKI on both the Neuromorphic MNIST (N-MNIST) and the Keyword Spotting k(KWS) tasks, achieving 98.0 % accuracy at 119.8 nJ/inference and 93.0 % accuracy at 546.5 nJ/inference respectively.
A Linear Implementation of an Analog Resonate-and-Fire Neuron
Nov 15, 2025Oscillatory dynamics have recently proven highly effective in machine learning (ML), particularly through State-Space-Models (SSM) that leverage structured linear recurrences for long-range temporal processing. Resonate-and-Fire neurons capture such oscillatory behavior in a spiking framework, offering strong expressivity with sparse event-based communication. While early analog RAF circuits employed nonlinear coupling and suffered from process sensitivity, modern ML practice favors linear recurrence. In this work, we introduce a resonate-and-fire (RAF) neuron, built in 22nm Fully-Depleted Silicon-on-Insulator technology, that aligns with SSM principles while retaining the efficiency of spike-based communication. We analyze its dynamics, linearity, and resilience to Process, Voltage, and Temperature variations, and evaluate its power, performance, and area trade-offs. We map the characteristics of our circuit into a system-level simulation where our RAF neuron is utilized in a keyword-spotting task, showing that its non-idealities do not hinder performance. Our results establish RAF neurons as robust, energy-efficient computational primitives for neuromorphic hardware.
Traces Propagation: Memory-Efficient and Scalable Forward-Only Learning in Spiking Neural Networks
Sep 16, 2025Spiking Neural Networks (SNNs) provide an efficient framework for processing dynamic spatio-temporal signals and for investigating the learning principles underlying biological neural systems. A key challenge in training SNNs is to solve both spatial and temporal credit assignment. The dominant approach for training SNNs is Backpropagation Through Time (BPTT) with surrogate gradients. However, BPTT is in stark contrast with the spatial and temporal locality observed in biological neural systems and leads to high computational and memory demands, limiting efficient training strategies and on-device learning. Although existing local learning rules achieve local temporal credit assignment by leveraging eligibility traces, they fail to address the spatial credit assignment without resorting to auxiliary layer-wise matrices, which increase memory overhead and hinder scalability, especially on embedded devices. In this work, we propose Traces Propagation (TP), a forward-only, memory-efficient, scalable, and fully local learning rule that combines eligibility traces with a layer-wise contrastive loss without requiring auxiliary layer-wise matrices. TP outperforms other fully local learning rules on NMNIST and SHD datasets. On more complex datasets such as DVS-GESTURE and DVS-CIFAR10, TP showcases competitive performance and scales effectively to deeper SNN architectures such as VGG-9, while providing favorable memory scaling compared to prior fully local scalable rules, for datasets with a significant number of classes. Finally, we show that TP is well suited for practical fine-tuning tasks, such as keyword spotting on the Google Speech Commands dataset, thus paving the way for efficient learning at the edge.
Real-Time Performance Benchmarking of TinyML Models in Embedded Systems (PICO: Performance of Inference, CPU, and Operations)
Sep 05, 2025



This paper presents PICO-TINYML-BENCHMARK, a modular and platform-agnostic framework for benchmarking the real-time performance of TinyML models on resource-constrained embedded systems. Evaluating key metrics such as inference latency, CPU utilization, memory efficiency, and prediction stability, the framework provides insights into computational trade-offs and platform-specific optimizations. We benchmark three representative TinyML models -- Gesture Classification, Keyword Spotting, and MobileNet V2 -- on two widely adopted platforms, BeagleBone AI64 and Raspberry Pi 4, using real-world datasets. Results reveal critical trade-offs: the BeagleBone AI64 demonstrates consistent inference latency for AI-specific tasks, while the Raspberry Pi 4 excels in resource efficiency and cost-effectiveness. These findings offer actionable guidance for optimizing TinyML deployments, bridging the gap between theoretical advancements and practical applications in embedded systems.